Artykuł Zwrócenie własnego obiektu odpowiedzi HTTP 400 w ramach automatycznej walidacji stanu modelu w ASP.NET Core pochodzi z serwisu DevKR.
]]>Domyślna automatyczna odpowiedź HTTP 400
W ASP.NET Core, gdy stosujemy atrybut ApiController na kontrolerze następuje automatyczne sprawdzenie poprawności przesłanego obiektu. W przypadku nieprawidłowej walidacji obiektu zostanie automatycznie zwrócony kod błędu HTTP 400. Nie nastąpi tu wejście do ciała akcji.
Na początek przekonajmy się jak to działa w praktyce. Stworzyłem VikingsController z akcją POST. Walidacja dla modelu Viking została skonfigurowana za pomocą FluentValidation. Osoby zainteresowane podstawami biblioteki do walidacji, odsyłam do mojego wcześniejszego artykułu „Fluent Validation z ASP.NET Core Web API„.
using API.Interfaces;
using API.Models;
using Microsoft.AspNetCore.Mvc;
namespace API.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class VikingsController : ControllerBase
{
private readonly IVikingsService _vikingsService;
public VikingsController(IVikingsService vikingsService) => _vikingsService = vikingsService;
[HttpPost]
public IActionResult Post(Viking viking)
{
_vikingsService.Add(viking);
return Created("", null);
}
}
}
namespace API.Models
{
public class Viking
{
public string Name { get; set; }
public string Email { get; set; }
public int Age { get; set; }
}
}
using API.Models;
using FluentValidation;
namespace API.Validators
{
public class VikingValidator : AbstractValidator
{
public VikingValidator()
{
RuleFor(v => v.Name).NotNull().NotEmpty();
RuleFor(v => v.Email).NotNull().NotEmpty().EmailAddress();
RuleFor(v => v.Age).InclusiveBetween(15, 50);
}
}
}
Wykorzystując narzędzie Postman wysyłam żądanie POST z obiektem nie spełniającym reguły walidacji.
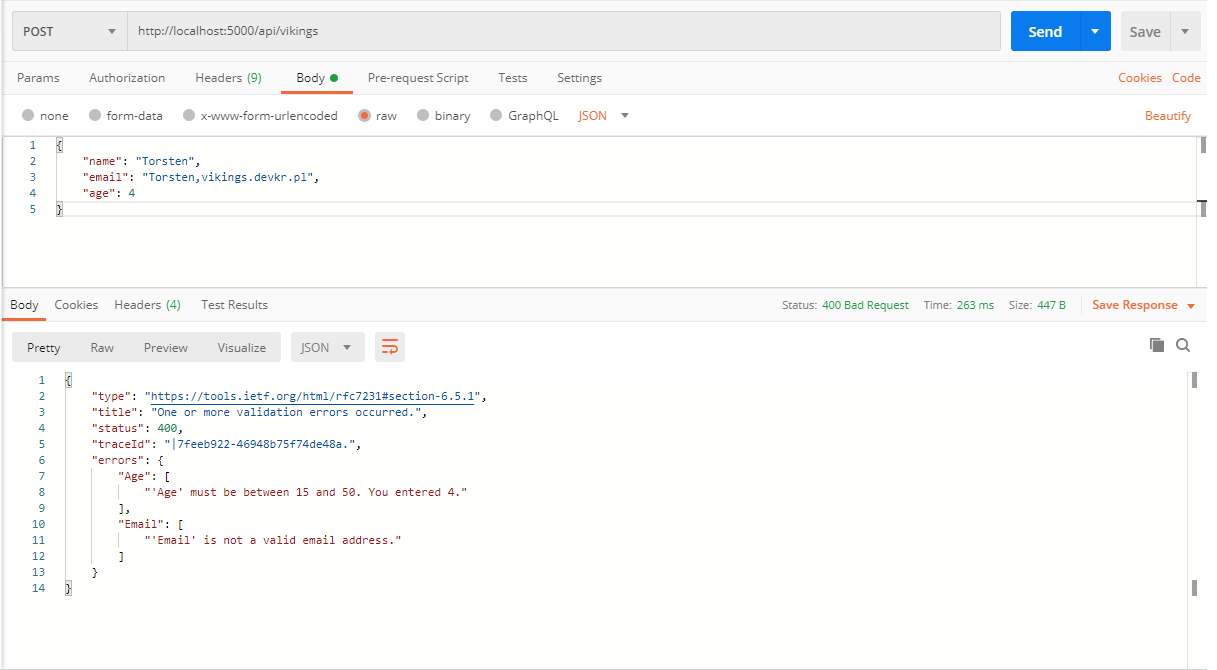
W odpowiedzi uzyskałem kod 400 Bad Request. Dla .NET Core 2.2 i nowszego domyślnym typem odpowiedzi jest obiekt ValidationProblemDetails. Odpowiedź zawiera pola jak na powyższym zrzucie z Postman. We wcześniejszych wersjach .NET Core (2.1 i starszych) domyślnym typem odpowiedzi jest obiekt SerializableError.
Własny obiekt odpowiedzi
Załóżmy, że nie podoba nam się format obiektu odpowiedzi ValidationProblemDetails, albo dodatkowo chcemy zalogować informacje o nieprawidłowej walidacji. Zauważcie, że w ciele akcji POST nie następuje sprawdzenie ModelState. Gdy stosujemy atrybut APIController, ASP.NET Core robi to z automatu za nas. Jak zatem obsłużyć automatyczną odpowiedź na błąd wynikający z przesłania nieprawidłowego obiektu.
Pierwszą opcją jest cofnięcie się do starego rozwiązania i wyłącznie automatycznej obsługi błędu 400. Możemy to zrobić poprzez usunięcie atrybutu APIController z kontrolera, albo dokonać tego poprzez ustawienie właściwości SuppressModelStateInvalidFilter na wartość true w metodzie ConfigureServices w klasie Startup.
services
.AddControllers()
.ConfigureApiBehaviorOptions(options => { options.SuppressModelStateInvalidFilter = true; });
Sprawdźmy poprawność powyższej konfiguracji. Dorzuciłem sprawdzenie ModelState w ciele akcji POST i wysłałem takie jak wcześniej żądanie POST z narzędzia Postman. Jak widać na poniższym zrzucie, nie dostaliśmy automatycznej odpowiedzi, tylko program zatrzymał się na breakpoint postawionym w miejscu obsługi błędu.

Wadą powyższego rozwiązania jest powielenie kodu sprawdzającego stan walidacji modelu w pozostałych akcjach kontrolerów. Zastanówmy się jak to zrobić globalnie.
Drugą opcją to pójście dalej z duchem zmian wprowadzonych w kolejny wersjach .NET Core. Czyli zostawiamy mechanizm automatycznej odpowiedzi. W celu podmiany domyślnego typu odpowiedzi na obiekt ErrorDetails wykorzystujemy InvalidModelStateResponseFactory. Zdefiniujmy na początek nasz model ErrorDetails.
using System.Collections.Generic;
using System.Text.Json;
namespace API.Models
{
public class ErrorDetails
{
public int StatusCode { get; set; }
public List ErrorMessages { get; set; }
public ErrorDetails(int statusCode, List errorMessages)
{
StatusCode = statusCode;
ErrorMessages = errorMessages;
}
public override string ToString() => JsonSerializer.Serialize(this);
}
}
W celu wyciągnice kolekcji komunikatów błędów walidacji dodałem extension method (GetErrorMessages) dla klasy ModelStateDictionary.
using System.Collections.Generic;
using System.Linq;
using Microsoft.AspNetCore.Mvc.ModelBinding;
namespace API.Extensions
{
public static class ModelStateDictionaryExtension
{
public static List GetErrorMessages(this ModelStateDictionary modelState)
=> modelState.Keys.SelectMany(key => modelState[key].Errors.Select(x => $"{key} : [{x.ErrorMessage}]")).ToList();
}
}
Została jeszcze konfiguracja zwracania obiektu ErrorDetails zamiast domyślnego ValidationProblemDetails. Zmieniamy aktualną konfigurację na poniższą w metodzie ConfigureServices w klasie Startup. InvalidModelStateResponseFactory to delegat wywołany na akcje z ApiControllerAttribute, konwertuje nieprawidłowy ModelStateDictionary na IActionResult.
services.AddControllers()
.AddFluentValidation(fv =>
{
fv.RegisterValidatorsFromAssemblyContaining();
fv.LocalizationEnabled = false;
})
.ConfigureApiBehaviorOptions(options =>
{
options.InvalidModelStateResponseFactory = context =>
{
var errorMessages = context.ModelState.GetErrorMessages();
var errorDetails = new ErrorDetails((int) HttpStatusCode.BadRequest, errorMessages);
var result = new BadRequestObjectResult(errorDetails)
{ContentTypes = {MediaTypeNames.Application.Json, MediaTypeNames.Application.Xml}};
return result;
};
});
Wykonałem jeszcze raz to samo żądanie, ale tym razem już nie dostałem domyślnego obiektu, tylko nasz ErrorDetails. Misja powiodła się, udało zmienić się domyślny obiekt odpowiedzi na własną implementację. Powodzenia i zapraszam do lektury starszych wpisów, oraz do oczekiwania na kolejne 
Artykuł Zwrócenie własnego obiektu odpowiedzi HTTP 400 w ramach automatycznej walidacji stanu modelu w ASP.NET Core pochodzi z serwisu DevKR.
]]>Artykuł Komentarze XML w Swagger UI dla ASP.NET Core Web API pochodzi z serwisu DevKR.
]]>Dokumentacja XML
W pierwszej kolejności musimy włączyć generowanie dokumentacji XML w ustawianiach projektu. Wspomnę na wstępie, że w powyższym artykule bazuję na API w ASP.NET Core 3.1. Edytujemy plik
true $(NoWarn);1591
Ustawiając wartość true dla właściwości GenerateDocumentationFile włączamy generowanie dokumentacji xml w trybie Debug i Release. To ustawienie także powoduję wyświetlenie ostrzeżeń w całym projekcie dla klas i metod, które nie zawierają opisów.

W trzeciej dodanej linii (NoWarn) ignorujemy ostrzeżenia w całym projekcie dla kodu 1591.
Konfiguracja Swagger
W drugim kroku musimy skonfigurować Swagger, aby używał wygenerowane pliki dokumentacji XML na UI. Konfiguracja Swagger odbywa się w klasie Startup. W celu wydzielenia logiki powiązanej z Swagger w jedno miejsce w projekcie utworzyłem klasę SwaggerMiddlewareExtensions z implementacją extension method. Metody wykorzystywane są do rejestracji Swagger middleware w pipeline. W celu dodania komentarzy xml do Swagger wywołujemy metodę IncludeXmlComments.
using System;
using System.IO;
using System.Reflection;
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.OpenApi.Models;
namespace RunnerTracker.API.Extensions.Middleware
{
public static class SwaggerMiddlewareExtensions
{
public static IServiceCollection AddCustomSwagger(this IServiceCollection services)
{
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new OpenApiInfo { Title = "Runner Tracker API", Version = "v1" });
var xmlFile = $"{Assembly.GetExecutingAssembly().GetName().Name}.xml";
var xmlPath = Path.Combine(AppContext.BaseDirectory, xmlFile);
c.IncludeXmlComments(xmlPath);
});
return services;
}
public static IApplicationBuilder UseCustomSwagger(this IApplicationBuilder app)
{
app.UseSwagger();
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "Runner Tracker API V1");
c.RoutePrefix = string.Empty;
});
return app;
}
}
}
Metody AddCustomSwagger i UseCustomSwagger wywołujemy w klasie Startup.
Komentarze XML na UI
W celu zaprezentowania efektu konfiguracji musimy w trzecim kroku do kontrolera napisać kilka summary do akcji. Poniżej przykład RunnerController.
using System.Collections.Generic;
using System.Threading.Tasks;
using MediatR;
using Microsoft.AspNetCore.Mvc;
using RunnerTracker.API.Domain.Runners.Commands;
using RunnerTracker.API.Domain.Runners.Dtos;
using RunnerTracker.API.Domain.Runners.Queries;
namespace RunnerTracker.API.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class RunnerController : ControllerBase
{
private readonly IMediator _mediator;
public RunnerController(IMediator mediator)
{
_mediator = mediator;
}
///
/// Get runner by id
///
///
/// Here are remarks
///
/// Runner id
/// Runner
[HttpGet("{runnerId}")]
public async Task> Get(int runnerId)
{
var runner = await _mediator.Send(new GetRunnerDetailQuery() {RunnerId = runnerId});
return Ok(runner);
}
///
/// Get all runners
///
/// List of runners
[HttpGet]
public async Task>> GetAll()
{
var runners = await _mediator.Send(new GetRunnersQuery());
return Ok(runners);
}
///
/// Add new runner
///
/// Runner data
/// Runner id
[HttpPost]
public async Task Create(CreateRunnerCommand command)
{
var runnerCreatedDto = await _mediator.Send(command);
return CreatedAtAction(nameof(Get), new {runnerId = runnerCreatedDto.RunnerId}, runnerCreatedDto);
}
///
/// Update an existing runner
///
/// Runner data
[HttpPut]
public async Task Change(UpdateRunnerCommand command)
{
await _mediator.Send(command);
return NoContent();
}
///
/// Delete a runner
///
/// Runner id
[HttpDelete("{runnerId}")]
public async Task Delete(int runnerId)
{
await _mediator.Send(new DeleteRunnerCommand() {RunnerId = runnerId});
return NoContent();
}
}
}
Mamy opisy, tym samym możemy uruchomić API i zobaczyć efekt wykonanej pracy. Na poniższym screenie, widzimy opisy akcji przy url punktu końcowego w Swagger UI.
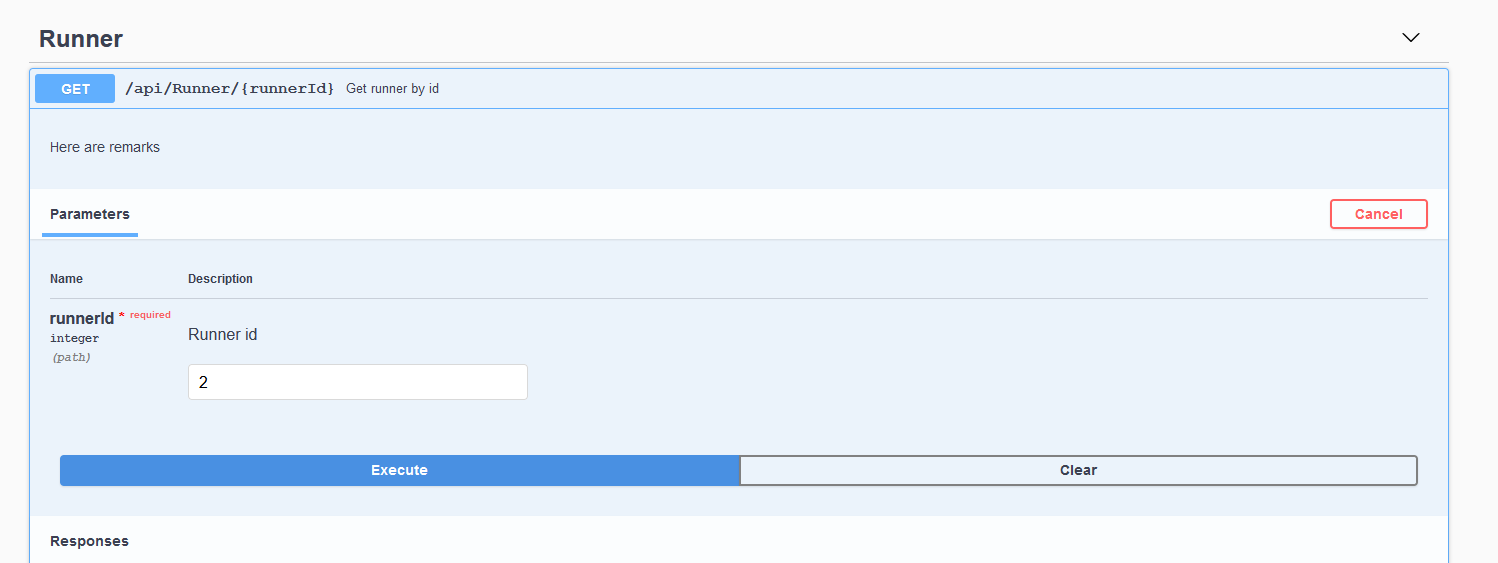
Przejdźmy do metody GET, na zrzucie widać opisy z sekcji summary, remarks i param.
Podsumowanie
Czwartego kroku już nie ma, skończone. Biblioteka Swagger umożliwia generowanie dokumentacji w prosty sposób dla API. Wykonując tylko trzy kroki, pokazałem jak dla projektu ASP.NET Core API wygenerować dokumentacje Swagger UI z komentarzami XML. Do kolejnego wpisu
Artykuł Komentarze XML w Swagger UI dla ASP.NET Core Web API pochodzi z serwisu DevKR.
]]>Artykuł Health Checks w ASP.NET Core pochodzi z serwisu DevKR.
]]>Podstawowy Health Check
Podstawowa konfiguracja zapewnia sprawdzenie dostępności usługi tzw. liveness. W ASP.NET Core paczka Microsoft.AspNetCore.Diagnostics.HealthChecks jest wykorzystywana do dodania health check-u w aplikacji. Na ten moment nie musimy pobierać żadnej dodatkowej paczki z NuGet, mamy wszystko dostępne od razu z pudełka po utworzeniu projektu API w ASP.NET Core 3.1. Otwórzmy naszą klasę Startup i zarejestrujmy usługę health checks poprzez wywołanie metody AddHealthChecks w metodzie ConfigureServices. Zostało nam jeszcze stworzenie punktu końcowego do monitorowania naszego API poprzez wywołanie metody MapHealthChecks w metodzie Configure.
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
namespace API
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddHealthChecks();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.MapHealthChecks("/health");
});
}
}
}
Nie mamy skonfigurowanych dodatkowych ustawień, jeśli API działa to dostaniemy odpowiedź Healthy. Sprawdźmy zatem nasz endpoint /health w przeglądarce.
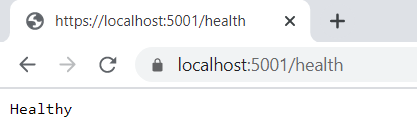
W odpowiedzi uzyskaliśmy status usługi w postaci zwykłego tekstu. Wyróżniamy trzy statusy usług: HealthStatus.Healthy, HealthStatus.Degraded oraz HealthStatus.Unhealthy. Podobnym wzorcem weryfikującym czy serwer/usługa działa jest tzw. PING PONG, który działa np. w Redis. W Redis CLI wywołujemy komendę PING i oczekujemy w przypadku uruchomionego serwera odpowiedzi PONG.
Implementujemy własny Health Check
Pakiet Microsoft.AspNetCore.Diagnostics.HealthChecks nie zawiera żadnych wbudowanych rozwiązań, stanowi jedynie bazę do dalszej implementacji. W celu stworzenia własnego rozwiązania należy zaimplementować w klasie interfejs IHealthCheck. Wszystko opiera się na implementacji asynchronicznej metody CheckHealthAsync, która zwraca status naszej usługi jako obiekt HealthCheckResult. W celu pokazania, że nie zawsze zwracany jest status healthy, wprowadzimy losowość w implementacji.
using System;
using System.Threading;
using System.Threading.Tasks;
using Microsoft.Extensions.Diagnostics.HealthChecks;
namespace API.HealthChecks
{
public class MyHealthCheck : IHealthCheck
{
public Task CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = new CancellationToken())
{
if (new Random().Next(1,10) % 2 == 0)
{
return Task.FromResult(HealthCheckResult.Healthy("Success"));
}
return Task.FromResult(HealthCheckResult.Unhealthy(description: "Failed"));
}
}
}
Został jeszcze jeden krok, czyli rejestracja MyHealthCheck za pomocą metody AddCheck w metodzie ConfigureServices.
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddHealthChecks()
.AddCheck("My custom health check");
}
Ze względu na wprowadzenie losowości uzyskujemy już nie tylko status healthy, ale także status unhealthy. Przejdźmy teraz do bardziej życiowego przykładu i zaimplementujmy health check dla SQL Server. U mnie instancja SQL Server będzie uruchamiana z poziomu Dockera. Do odpytania bazy danych wspomogę się biblioteką Dapper. W związku z tym z NuGet musimy zainstalować dwie paczki Dapper i Microsoft.Data.SqlClient.
using System;
using System.Threading;
using System.Threading.Tasks;
using Dapper;
using Microsoft.Data.SqlClient;
using Microsoft.Extensions.Diagnostics.HealthChecks;
namespace API.HealthChecks
{
public class SqlServerHealthCheck : IHealthCheck
{
private readonly string _connectionString;
public SqlServerHealthCheck(string connectionString)
{
_connectionString = connectionString ?? throw new ArgumentNullException(nameof(connectionString));
}
public async Task CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = new CancellationToken())
{
try
{
using (var conn = new SqlConnection(_connectionString))
{
await conn.QueryAsync($"SELECT 1", cancellationToken);
return HealthCheckResult.Healthy();
}
}
catch (Exception ex)
{
return new HealthCheckResult(context.Registration.FailureStatus, exception: ex);
}
}
}
}
W następnym kroku musimy dodać sekcje ze swoim connection string do appsettings.json.
"sqlServerConnectionString": "Server=;Database= ;User Id= ; Password= ;",
Zostało jeszcze zarejestrowanie SqlServerHealthCheck. Ze względu, że przekazujemy connection string jako argument użyjemy metody AddTypeActivatedCheck zamiast AddCheck.
public void ConfigureServices(IServiceCollection services)
{
var sqlServerConnectionString = Configuration["sqlServerConnectionString"];
services.AddControllers();
services.AddHealthChecks()
.AddCheck("My custom health check")
.AddTypeActivatedCheck("Sql Server", args: new object[] {sqlServerConnectionString});
}
Możemy MyHealthCheck za komentować, by mieć pewność, że komunikacja z Microsoft SQL Server działa prawidłowo.
AspNetCore.Diagnostics.HealthChecks
Zamiast implementować każdy health check samemu, możemy wykorzystać dostępną paczkę AspNetCore.Diagnostics.HealthChecks. Jeśli przeglądaliście dokumentacje Microsoftu w tym temacie, to kilka razy w fioletowej ramce wyświetlił się wam komunikat „AspNetCore.Diagnostics.HealthChecks isn’t maintained or supported by Microsoft.”. Łatwo skojarzyć tę paczkę z Microsoft.AspNetCore.Diagnostics.HealthChecks, przez co wszystko wydaje się, że jest przez Microsoft wspierane. Powyższa paczka zawiera implementacje dla wielu usług np.:
- Sql Server
- MySql
- Oracle
- Sqlite
- RavenDB
- Postgres
- EventStore
- RabbitMQ
- IbmMQ
- Elasticsearch
- Solr
- Redis
- System: Disk Storage, Private Memory, Virtual Memory, Process, Windows Service
- Azure Service Bus, Azure Storage: Blob, Azure Key Vault, Azure DocumentDb, Azure IoT Hub
- Amazon DynamoDb, Amazon S3
- Network: Ftp, SFtp, Dns, Tcp port, Smtp, Imap
- MongoDB
- Kafka
- Identity Server
- Uri: single uri and uri groups
- Consul
- Hangfire
- SignalR
- Kubernetes
Reasumując, jest w czym wybierać z powyższej listy. W dalszej części wpisu zaprezentuję integracje z brokerem wiadomości RabbitMQ. Z NuGet tym razem pobieram dwie paczki: AspNetCore.HealthChecks.Rabbitmq i RabbitMQ.Client. W kolejnym kroku dodaję sekcje z ustawieniami RabbitMQ do appsettings.json. Wykorzystam tu domyślne ustawienia.
"rabbitconnstr": "amqp://guest:guest@:5672",
Na koniec rejestruję usługę RabbitMQ poprzez wywołanie metody AddRabbitMQ w ConfigureServices.
public void ConfigureServices(IServiceCollection services)
{
var sqlServerConnectionString = Configuration["sqlServerConnectionString"];
var rabbitConnectionString = Configuration["rabbitconnstr"];
services.AddControllers();
services.AddHealthChecks()
.AddCheck("My custom health check")
.AddTypeActivatedCheck("Sql Server", args: new object[] {sqlServerConnectionString})
.AddRabbitMQ(rabbitConnectionString: rabbitConnectionString);
}
Z pewnością przyznacie, że rejestracja health check-a z tym pakietem jest dość przyjemna. Żeby nie pobierać paczek w ciemno zobaczmy co wchodzi w skład takiej paczki np. AspNetCore.HealthChecks.Rabbitmq. Przede wszystkim widzimy, że mamy tylko dwie klasy na repozytorium dla powyższego pakietu. Pierwsza to implementacja healt check-a dla RabbitMQ, a druga rozszerza IHealthChecksBuilder o metody do wstrzyknięcia implementacji RabbitMQHealthCheck. Społeczność wypuszcza wiele różnych pakietów dla usług zewnętrznych. Czy z nich będziecie korzystać, to już zależy od Was.
Health Checks UI
Nadchodzi chwila dla miłośników UI. Zaprezentujmy statusy w interfejsie graficznym. W związku z tym musimy zainstalować dwie paczki: AspNetCore.HealthChecks.UI i AspNetCore.HealthChecks.UI.Client. Za pomocą metody AddHealthChecksUI rejestrujemy UI w ConfigureServices.
services.AddHealthChecksUI();
Następnie wywołujemy metodę MapHealthChecksUI w Configure. Należy skonfigurować ResponseWriter, aby używał UIResponseWriter.WriteHealthCheckUIResponse. Poniższa konfiguracja zapewnia nam zwrócenie wyniku odpowiedzi w formacie JSON. Wymagane to jest przez interfejs HealthCheck UI, aby uzyskać szczegółowe informacje o skonfigurowanych health check-ach.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.MapHealthChecks("/health", new HealthCheckOptions()
{
Predicate = _ => true,
ResponseWriter = UIResponseWriter.WriteHealthCheckUIResponse
});
endpoints.MapHealthChecksUI();
});
}
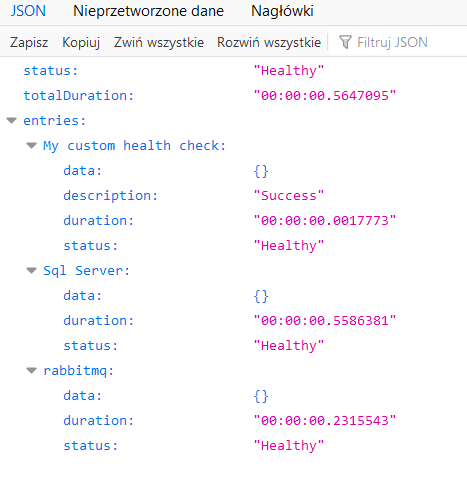
W ostatnim kroku w ramach uruchamiania UI należy dodać konfiguracje do appsettings.json. Konfiguracja wskazuje, z jakiego punktu końcowego ma UI skorzystać, by uzyskać informacje o stanie API.
"HealthChecks-UI": {
"HealthChecks": [;
{
"Name": "API",
"Uri": "https://localhost:5001/health"
}
],
"EvaluationTimeOnSeconds": 5,
"MinimumSecondsBetweenFailureNotifications": 60
}
W celu podglądu UI wchodzimy na endpoint /healthchecks-ui, który jest domyślnym URL dla UI.
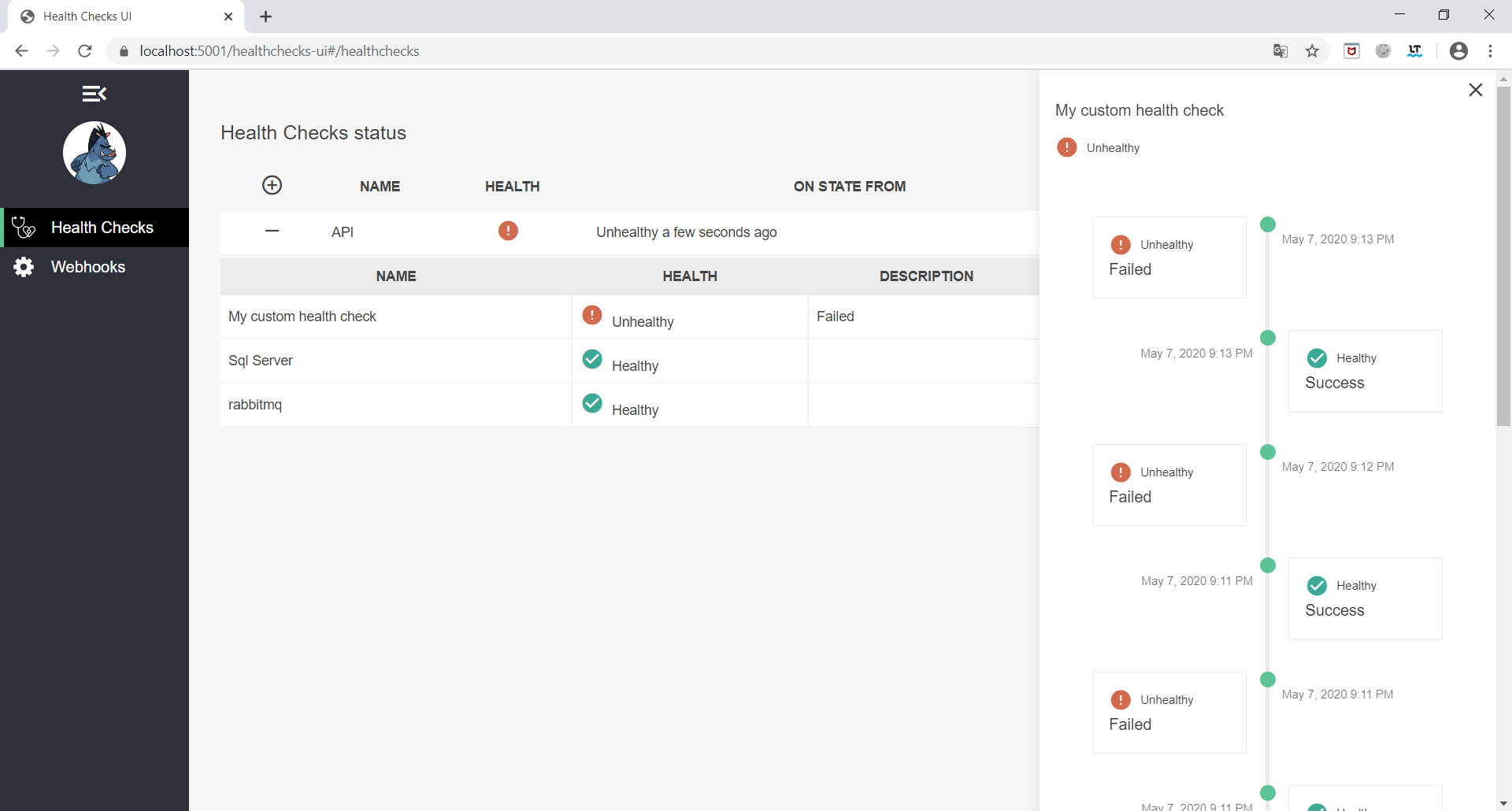
Podsumowanie
W ASP.NET Core dostaliśmy wbudowane wsparcie do badania stanu aplikacji poprzez Health Checks Middleware. Powyższe przykłady pokazały, że konfiguracja health checks w ASP.NET Core jest łatwa. Podsumowując ten wpis nie wyczerpuje całego tematu monitorowania usług. Zachęcam do lektury dokumentacji oraz dodania monitoringu metryk sprzętowych (dysk, RAM). Mam nadzieję, że ten post był przydatny, do zobaczenia.
Artykuł Health Checks w ASP.NET Core pochodzi z serwisu DevKR.
]]>Artykuł Import Swagger API do Postman dla ASP.NET Core Web API pochodzi z serwisu DevKR.
]]> Mamy do sprawdzenia API, które ma dokumentacje w Swagger. Możemy z poziomu UI wywołać i sprawdzić odpowiedzi dla żądań. Jednak w celu automatyzacji najlepiej napisać żądania i testy w Postman. Unikniemy dzięki temu manualnej roboty w Swagger UI. Kolekcje żądań po zakończeniu pracy możemy wypchnąć na repozytorium kodu np. Git. Super automatyzacja, ale chwila czy w Postman wszystkie parametry i żądania musimy ręcznie zadeklarować? Przecież to będzie dużo niewdzięcznej roboty. A co jeśli dałoby się wygenerować szablony żądań w Postman. Czas na sztuczkę, by ułatwić sobie życie przy pisaniu żądań w narzędziu Postman. Chcecie poznać sztuczkę, to zapraszam do wpisu.
Konfiguracja Swagger
Zacznijmy od stworzenia nowego projektu ASP.NET Core Web API w VS 2019. Wykorzystam projekt z domyślnego szablonu i nazwę go API. Leniwy programista nie będzie implementował nowych endpoint-ów. Do prezentacji sztuczki wystarczy domyślny projekt. Na początek do projektu w ASP.NET Core 3.1 dodajemy paczkę Swashbuckle.AspNetCore z NuGet.

Po dodaniu paczki przechodzimy do konfiguracji Swagger Middleware w klasie Startup.cs. W metodzie ConfigureService dodajemy Swagger do kolekcji usług. Natomiast w metodzie Configure włączamy obsługę generowania Swagger jako JSON Endpoint i Swagger UI.
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.OpenApi.Models;
namespace API
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new OpenApiInfo { Title = "API", Version = "v1", Description = "API tajnego projektu."});
});
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseSwagger();
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "API v1");
c.RoutePrefix = string.Empty;
});
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
}
}
Wykonując powyższe kroki, skonfigurowaliśmy usługę Swagger w najprostszej postaci i mamy ją gotową do użycia. Jeśli chcemy wyświetlić Swagger UI z automatu przy uruchamianiu API, musimy ustawić właściwość launchBrowser na true w launchSettings.json. Warto także ustawić launchUrl na pustą wartość „” w tym samym pliku. Rezultatem powyższej konfiguracji będzie wyświetleni się Swagger UI po uruchomieniu projektu jak na poniższym screenie.
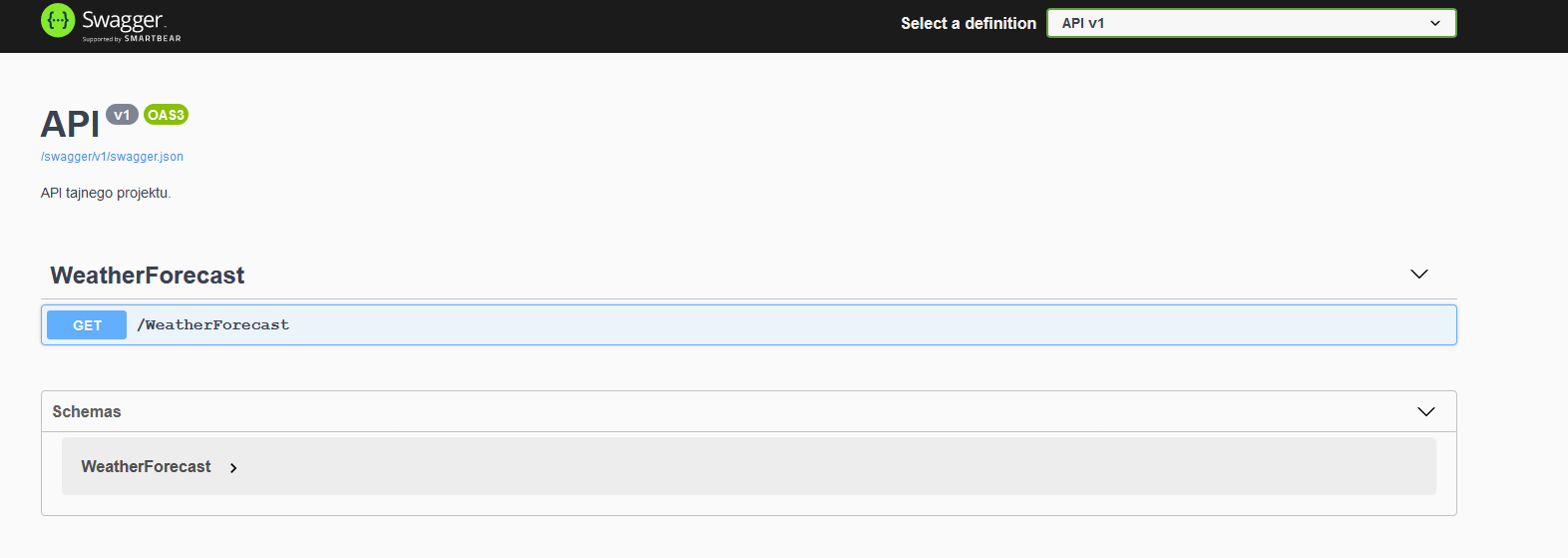
Import Swagger API do Postman
Po uruchomieniu API z Swagger możemy przejść do najważniejszego punktu niniejszego wpisu. Importujemy API do Postman, poprzez wybranie opcji z menu File -> Import -> Import From Link. W polu podajemy JSON URL do naszego API, który jest dostępny z poziomu Swagger UI.

Po imporcie w kolekcji pokarzą się wszystkie dostępne akcje z API. W domyślny projekcie ASP.NET Core Web API jest dość skromnie, ale widzimy, że pojawiła się akcja GET.
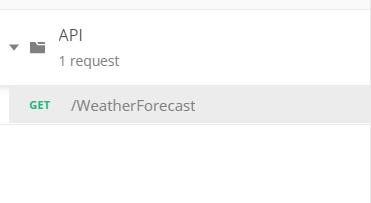
Podsumowanie
Wpis krótki, ale mam nadzieję, że zaprezentowana sztuczka niektórym zaoszczędzi ręcznej pracy w Postman Powodzenia na szlaku optymalizacji pracy.
Artykuł Import Swagger API do Postman dla ASP.NET Core Web API pochodzi z serwisu DevKR.
]]>Artykuł LF will be replaced by CRLF pochodzi z serwisu DevKR.
]]>Problem
Najlepiej wyjaśnić sposób poradzenia sobie z problem na jakimś przykładzie. Wyobraźmy sobie, że w ramach prac programistycznych zależy nam na uruchomieniu zainicjalizowanej bazy danych na SQL Server 2017 w kontenerze Docker. W celu wykonania zadania utworzę następujące pliki:
- docker-compose.yml (zawiera definicje kontenera SQL Server);
version: "3.7"
services:
mssqlServer:
image: microsoft/mssql-server-linux:2017-latest
container_name: "mssqlServer"
environment:
SA_PASSWORD: Qwerty1!
ACCEPT_EULA: Y
ports:
- "1433:1433"
restart: always
working_dir: /Scripts
volumes:
- ./Scripts:/Scripts
command: bash -c "sh createDB.sh & /opt/mssql/bin/sqlservr"
- createDB.sh (skrypt uruchamiający za pomocą narzędzia sqlcmd polecenia T-SQL z pliku createDatabase.sql);
#!/bin/ssh
sleep 20s
/opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P ${SA_PASSWORD} -i createDatabase.sql
- createDatabase.sql (plik zawiera polecenia T-SQL do utworzenia bazy danych o nazwie Mundial).
-- Create a new database called 'Mundial'
-- Connect to the 'master' database to run this snippet
USE master
GO
-- Create the new database if it does not exist already
IF NOT EXISTS (SELECT name FROM sys.databases WHERE name = N'Mundial')
CREATE DATABASE Mundial
GO
USE Mundial
GO
-- Create a new table called 'Players' in schema 'dbo'
-- Drop the table if it already exists
IF OBJECT_ID('dbo.Players', 'U') IS NOT NULL
DROP TABLE dbo.Players
GO
-- Create the table in the specified schema
CREATE TABLE dbo.Players
(
PlayersId INT NOT NULL IDENTITY(1,1) PRIMARY KEY, -- primary key column
FirstName [NVARCHAR](50) NOT NULL,
LastName [NVARCHAR](50) NOT NULL,
Nationality [NVARCHAR](50) NOT NULL,
Height tinyint NOT NULL,
Age tinyint NOT NULL,
Position [NVARCHAR](50) NOT NULL,
CurrentClub [NVARCHAR](50) NOT NULL,
MarketValue real NOT NULL
);
GO
-- Insert rows into table 'dbo.Players'
INSERT INTO dbo.Players
( -- columns to insert data into
[FirstName], [LastName], [Nationality], [Height], [Age], [Position], [CurrentClub], [MarketValue]
)
VALUES
( 'Jan', 'Kowalski', 'Poland', 185, 21, 'Left Wing', 'DRY Opole' , 1.2),
( 'Marian', 'Lewandowski', 'Poland', 160, 29, 'Centre-Forward', 'SOLID Warszawa' , 100.0),
( 'Adam', 'Peszkin', 'Poland', 185, 32, 'Left Wing', 'KISS Gdynia' , 2.3),
( 'Olaf', 'Majka', 'Poland', 210, 17, 'Keeper', 'YAGNI Gliwice' ,32.2)
GO
W powyższym wpisie pomijam kwestie instalacji narzędzi Docker i Docker Compose. Osoby zainteresowane tematem uruchomienia kontenera SQL Server 2017 w 3 krokach, zapraszam do wcześniejszego mojego wpisu Praca z SQL Server w Visual Studio Code.
Wszystko zostało elegancko zakodowane, sprawdzone i kontener uruchomił się prawidłowo. Tym samym czas dorzucić zmiany do repozytorium Git. Wykonujemy polecenie git add w celu dodania zmian z working copy do indexu. W oknie Git Bash wyświetliły się poniższe ostrzeżenia, ale jako zawodowi programiści nie będziemy się tym przejmować. Czy my możemy popełnić błąd obsługując gita W kolejnych krokach wykonujemy git pull, checkout, rebase, merge i push. Praca zakończona, czas na zasłużony odpoczynek.
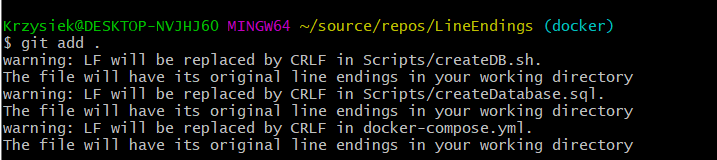
Na kolejny dzień wracamy do naszego repo, przełączamy się na branch develop i próbujemy zbudować kontener wykonując w głównym folderze repozytorium komendę docker-compose up -d.
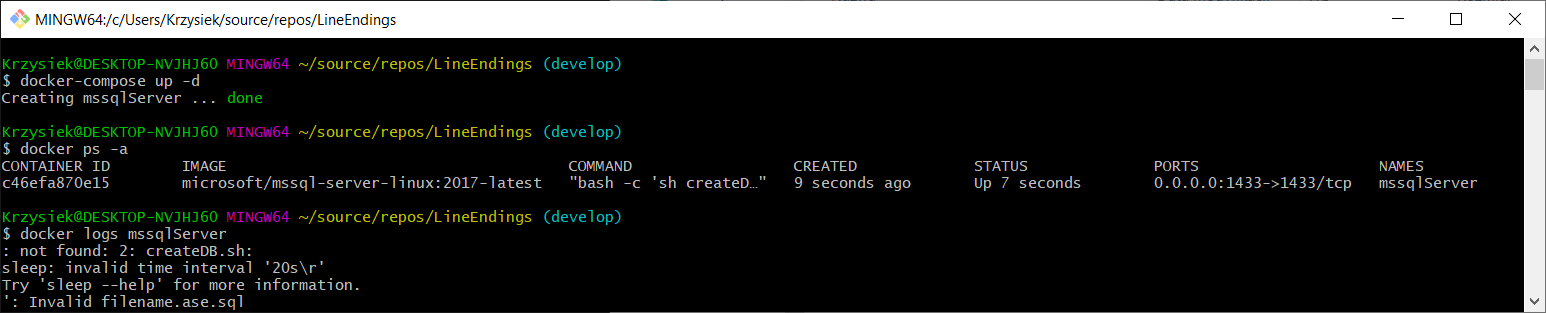
Po podłączeniu się do SQL Server nie widać bazy Mundial, ale jak to? Zobaczmy co tam Git Bash pokazał, kontener utworzony (done), status kontenera Up, czyli wszystko prawidłowo. Podejrzyjmy zatem logi dla kontenera mssqlServer. Co tu się dzieje mamy komunikaty „not found”, „invalid time interval” oraz „invalid filename”. Ale jak to przecież wczoraj wszystko działało. W historii gita nie ma od tego momentu żadnych dodatkowych zmian. Nie trać czasu, restart nie pomoże na taką magię.
Rozwiązanie
Zanim zaprezentuję możliwe rozwiązania, zdefiniujemy przyczynę. Po tytule wpisu można domyślić się, że chodziło o konwersje plików dokonanych przez gita. Skrypty wyklepałem w nano, gdzie znak końca linii był LF tak jak w Linuxie. Nasz kontener korzysta z obrazu zawierającego SQL Server 2017 na Ubuntu.

Teraz przypomnijmy sobie ostrzeżenia wyświetlone przez system kontroli wersji. Zgodnie z ich treścią dla skryptów znak końca bieżącej linii LF zostanie zastąpiony przez dwa znaki CRLF reprezentujące koniec linii w plikach np. w systemie Windows w trakcie operacji git checkout. W sytuacji uruchomienia skrypt createDB.sh pod Ubuntu został źle zinterpretowany ze względu na dwa znaki CRLF. W tym przypadku oczekiwany był znaku końca linii LF używany np. w systemie Ubuntu. Przyczyna zdiagnozowana, ale jak to teraz naprawić.
Globalne ustawienia dla końca linii
Pierwszym sposobem jest normalizacja zakończenia linii na poziomie systemowym. W tym celu należy użyć polecenia git config –global core.autocrlf , które zmieni sposób obsługi zakończenia linii w git.
git config --global core.autocrlf input git config --global core.autocrlf true git config --global core.autocrlf false
Zgodnie z powyższymi poleceniami dla core.autocrlf możemy ustawić trzy wartości:
- true – powoduje zmianę CRLF na LF podczas commita do repozytorium. W przypadku operacji pobrania kodu z repozytorium lub wykonania instrukcji git checkout zostanie dokonana zmiana LF na CRLF. W repozytorium znaki końca linii przechowywane są jako LF.
- false – nie powoduje zmiany CRLF na LF i odwrotnie. Znaki LF i CRLF będą zapisywane do repozytorium Git.
- input – powoduje zmianę CRLF na LF podczas commita do repo. W przypadku operacji pobrania kodu z repozytorium lub wykonania instrukcji git checkout nie jest wykonywana konwersja. W repozytorium znaki końca linii przechowywane są jako LF.
Pierwsza wartość true zalecana dla systemu Windows nie sprawdzi się w moim aktualnym przypadku. Wartość input rekomendowana dla systemów Linux/Mac zdałaby tutaj rozwiązanie, ale w przypadku innych projektów na komputerze mogła być problematyczna. Ostatnią wartość false odrzucam, ze względu na możliwy bałagan z CRLF i LF w repozytorium. W takim przypadku najlepszą opcją będzie zarządzanie końcem linii na poziomie repozytorium.
Zarządzanie końcem linii na poziomie repozytorium
W powyższym podejściu zarządzamy końcem linii, konfigurując plik .gitattributes dla konkretnego repozytorium. Konfiguracja w pliku .gitattributes zastępuje globalną konfiguracje dla wskazanego repozytorium. Plik .gitattributes tworzymy w głównym folderze repozytorium. Konfiguracja w pliku .gitattributes polega na powiązaniu wzorca (np. plików o wskazanym rozszerzeniu) z atrybutami (np. konfiguracją końca linii). Dodajmy plik .gitattributes o poniższej zawartości do naszego repozytorium. Oczekujemy, że w naszym lokalnym folderze dla plików o rozszerzeniu .sh i .sql zostanie ustawiony znak końca linii LF.
* text=auto *.sh text eol=lf *.sql text eol=lf
Teraz dodamy znormalizowane pliki, poprzez wykonanie poniższego polecenia.
git add --renormalize .
Powyższe polecenie nie spowoduje aktualizacji znaku/znaków linii zakończenia w plikach z working copy. W ramach aktualizacji w working copy należy wykonać poniższe instrukcje. Tutaj trzeba mieć na uwadze usunięcie plików nieśledzonych przez gita.
git rm --cached -r . git reset --hard
W programie Notepad ++ możemy podejrzeć czy dla pliku createDB.sh znak końca linii to LF. Sprawdzimy teraz, czy uda się postawić bazę danych ze skryptu. Wykonujemy ponownie komendę docker-compose up -d w głównym folderze repozytorium.

W ostatnim kroku wykorzystując LINQPad 5 połączyłem się z SQL Server i pobrałem zawartość tabeli Players z bazy Mundial. Po zakończeniu procesu normalizacji plików ponownie udało się prawidłowo utworzyć kontener SQL Server w narzędziu Docker.
Artykuł LF will be replaced by CRLF pochodzi z serwisu DevKR.
]]>Artykuł Testy konwencji pochodzi z serwisu DevKR.
]]>Testy konwencji
Na początek zastanówmy się, kiedy warto stosować testy konwencji i jaką wartość możemy wnieść implementując powyższe testy? Pierwsza myśl, jaka przychodzi mi do głowy to wprowadzenie świeżej osoby (nowy pracownik, stażysta, praktykant, osoba z innego zespołu) do aktualnie rozwijanego projektu. Każda nowa osoba potrzebuje czasu, by przywyknąć do standardów kodowania, które mogą różnić się od wcześniej im znanych. Uruchamiając testy konwencji lokalnie, możemy przed wypchnięciem kodu do zdalnego repozytorium zweryfikować czy wytwarzany kod jest zgodny z przyjętymi standardami. Alternatywą dla testów konwencji są narzędzia do statycznej analizy kodu.
Przykłady
Testy konwencji opierają się na mechanizmie refleksji. Z danego assembly wykorzystując refleksje uzyskujemy dostęp do szczegółowych informacjach o typach. Przejdźmy do pierwszego przykładu zaimplementowanego z wykorzystaniem NUnit. Jesteśmy leniwi i chcemy w naszym API zautomatyzować rejestracje instancji typu Repository w kontenerze IoC Autofac. W tym celu zaimplementowałem klasę RepositoryModule, której metoda odpowiada za wyszukiwanie i rejestracje zestawu typów zgodnie z określoną regułą (instancja implementuje marker interface IRepository). Pierwszy test zweryfikuje czy wszystkie interfejsy typu Repository ze wskazanej przestrzeni nazw dziedziczą marker interface IRepository
using System.Reflection;
using Api.Interfaces.Markers;
using Autofac;
namespace Api.IoC
{
public class RepositoryModule : Autofac.Module
{
protected override void Load(ContainerBuilder builder)
{
var assembly = typeof(RepositoryModule).GetTypeInfo().Assembly;
builder.RegisterAssemblyTypes(assembly)
.Where(x => x.IsAssignableTo())
.AsImplementedInterfaces()
.InstancePerLifetimeScope();
}
}
}
[Test]
public void When_RepositoryInterface_Expect_RepositoryInterfaceInheritsFromMarkerInterface()
{
var types = typeof(RepositoryModule).Assembly.GetTypes();
var interfacesThatDoesNotInheritFromMarkerInterface = types
.Where(t => t.Namespace.Equals("Api.Interfaces.Repositories"))
.Where(t => t.IsInterface)
.Where(i => i.GetInterface(nameof(IRepository)) == null)
.ToList();
Assert.IsEmpty(interfacesThatDoesNotInheritFromMarkerInterface);
}
W przypadku prawidłowej implementacji w ramach testu powinniśmy uzyskać pustą kolekcję. Przejdźmy do drugiego analizowanego przypadku. Załóżmy, że posiadamy metodę o następującej sygnaturze public async Task
[Test]
public void When_AsyncMethod_Expect_TheMethodNameEndsWithTheAsyncSuffix()
{
var methods = typeof(RepositoryModule).Assembly
.GetTypes()
.SelectMany(t => t.GetMethods(BindingFlags.NonPublic | BindingFlags.Public
| BindingFlags.Instance | BindingFlags.Static |
BindingFlags.DeclaredOnly))
.ToList();
var asyncMethodsWithoutAsyncSuffix = methods
.Where(m => m.GetCustomAttribute() != null)
.Where(m => m.Name.EndsWith("Async") == false)
.ToList();
Assert.IsEmpty(asyncMethodsWithoutAsyncSuffix);
}
Analogicznie jak w poprzednim teście w asercji sprawdzamy, czy kolekcja jest pusta. Zatrzymam się na trzech przykładach i na koniec sprawdzę, czy w API każda klasa Controller dziedziczy po klasie ControllerBase.
[Test]
public void When_Controller_Expect_ControllerInheritsFromControllerBase()
{
var types = typeof(RepositoryModule).Assembly.GetTypes();
var controllersThatDoesNotInheritControllerBase = types
.Where(t => t.Name.EndsWith("Controller"))
.Where(t => t.IsClass)
.Where(c => c.IsSubclassOf(typeof(ControllerBase)) == false)
.ToList();
Assert.IsEmpty(controllersThatDoesNotInheritControllerBase);
}
Jeśli otrzymaliście przy wszystkich testach konwencji kolor zielony, zadanie można uznać za zakończone sukcesem. W ramach dbania o czytelność testów warto kilka operacji wydzielić do extension method i także ograniczyć ilość wywołań where poprzez wykorzystanie operatora &.
Podsumowanie
Testy konwencji i narzędzia do statycznej analizy kodu wymuszają stosowanie przyjętych standardów dla kodu źródłowego w projekcie. Powyższe trzy przykłady to tylko początek przygody z testami. W ramach waszych projektów wystąpi wiele scenariuszy, których przestrzeganie ustrzeże zespól przed błędami w systemie i zapewni jednolitość kodu w projekcie.
Artykuł Testy konwencji pochodzi z serwisu DevKR.
]]>Artykuł Feature Toggle w .NET pochodzi z serwisu DevKR.
]]>Release Toggles
Release toggles jest alternatywą dla feature branch w systemach kontroli wersji. Rozpoczynając pracę w tradycyjnym podejściu dla funkcji tworzymy nową gałąź i implementujemy funkcje zgodnie z issue, a następnie scalamy kod. W przypadku stosowania przełączników, zespół pracuje na jednej gałęzi np. master i ukrywa aktualnie realizowane funkcje za pomocą przełącznika. W momencie zakończenia pracy nad funkcją i przekazaniem do testów, osoba z zespołu aktywuje funkcje. Czyli w praktyce stosujemy branch w kodzie zamiast fizycznego brancha w systemie kontroli wersji. Stosując to rozwiązanie odpada nam problem zarządzania, utrzymania, scalania wielu gałęzi kodu źródłowego. Wadą tego rozwiązania jest utrzymywanie nieaktywnego kodu na głównej gałęzi, aż korci by kod na szaro (martwy) usunąć. Na co dzień stosuję swoją piaskownice dla zadania, czyli tworzę w repo gałąź na funkcje, będąc świadom ewentualnych konfliktów z dużymi mergami. Chętnie w komentarzach poznam opinie osób, które na co dzień pracują z metodyką release toggle w systemie kontroli wersji. Tu nasuwa mi się pytanie, co z testami jednostkowymi dla nieaktywnego kodu? Jak u was wygląda konfiguracja feature toggle?
Business Toggles
W przypadku release toggles mówiliśmy o korzyściach dla zespołów projektowych, a business toggles dotyczą korzyści dla klienta (biznesu). Business toggles umożliwiają włączania/wyłączania funkcji w zależności od kryterium biznesowego. W praktyce możemy udostępnić funkcje w zależności od geolokalizacji, grupy użytkownika, aktywności, wieku użytkownika etc.. Na produkcji nie będziemy mieli „prostego” if-a, ale bardziej złożony warunek, który oprócz flagi określającej włączenie/wyłączenie funkcji, będzie także zawierać politykę udostępnienia funkcji.
Konfiguracja
Zarządzanie dostępnością funkcji w aplikacji może odbywać się na trzech poziomach konfiguracji:
- Compiled configuration
- Local configuration
- Centralized configuration
Compiled configuration
W powyższej opcji konfiguracja jest zaszyta na sztywno w kodzie źródłowym. W celu zmiany stanu funkcji za każdym razem należy zbudować nową aplikację. Jest to najgorsze rozwiązanie dla sterowania/synchronizacją aplikacji na produkcji. Zobaczmy jednak przykładowe implementacje dla „Compiled configuration”:
- Flaga (true/false)
var isSuperFeatureEnabled = true;
if (isSuperFeatureEnabled)
{
// implementation
}
Dla czytelności można utworzyć klasę z polami typu const (flagi).
- Dyrektywy preprocesora
#define SUPER_FEATURE #if (SUPER_FEATURE) //implementation #endif
Definiujemy (#define) ciąg znaków np. SUPER_FEATURE i w dyrektywie warunkowej #if sprawdzamy zdefiniowany symbol. Jeśli wartość logiczna jest prawdziwa zostanie wykonany kod między dyrektywą #if a #endif. Przykładowo dodając do definicji znak „_” np. _SUPER_FEATURE traktujemy, że funkcja ma być nieaktywna.
Local configuration
Wartości określające dostępność funkcji przechowywane są w plikach konfiguracyjnych aplikacji lub zmiennych środowiskowych. W porównaniu do opcji „Compiled configuration” nie trzeba w celu zmiany stanu funkcji budować nowej wersji aplikacji. Wystarczy zmienić wartość stanu (true/false) dla klucza w lokalnej konfiguracji. W przypadku, gdy aplikacja znajduje się na wielu maszynach, dochodzi problem synchronizacji konfiguracji.
- Odczyt z pliku konfiguracyjnego np. web.config
var isSuperFeatureEnabled = bool.Parse(ConfigurationManager.AppSettings["SuperFeature"]);
- Zmienne środowiskowe
var isSuperFeatureEnabled = Environment.GetEnvironmentVariable("SUPER_FEATURE");
if (isSuperFeatureEnabled)
{
// implementation
}
Centralized configuration
Przy tej konfiguracji wartości odczytywane są z centralnego punktu z konfiguracją. W tym podejściu rozwiązujemy problem synchronizacji aplikacji na wielu maszynach, oraz nie mamy potrzeby budowania nowej wersji aplikacji. Konfiguracja może być przechowywana w następujących lokalizacjach:
- Tabela w bazie danych
- Zewnętrzne narzędzie do przechowywania stanu aplikacji np. Consul, Feature Ops etc.
Dla wszystkich trzech konfiguracji mówiłem tylko o tym czy funkcja jest aktywna/nieaktywna. W przypadku uwzględnienia wybranego kryterium biznesowego, będziemy dodatkowo musieli w warunku sprawdzić wymaganie biznesowe np. czy funkcja dostępna tylko dla użytkowników z Wrocławia.
Do implementacji feature toggles w świecie .NET możemy skorzystać z zewnętrznych bibliotek np. FeatureSwitcher lub FeatureToggle. W przypadku własnej implementacji warto warunek wyekstraktować do zewnętrznej metody zdefiniowanej w interfejsie. W powyższej metodzie będzie sprawdzany aktualny stan funkcji na podstawie zdefiniowanej konfiguracji. Zdefiniowanie interfejsu zapewni nam możliwość zweryfikowania testami jednostkowymi kodu nowej funkcji.
Podsumowanie (Zalety vs Wady)
Feature toggle to dobra technika do rozwiązania problemu częstych, złożonych i problematycznych wdrożeń. Czy warto ją stosować w codziennej pracy? Przyjrzyjmy się na koniec zaletą i wadą feature toggle.
Zalety:
- mamy możliwość sterowania funkcjami systemu na środowisku produkcyjnymi. W przypadku pożaru możemy szybko wyłączyć nową funkcje, lub powrócić do starej wersji funkcji.
- minimalizacja ryzyka nowych funkcji
- możliwość testowania pod względem biznesowym na produkcji np. testujemy na określonej liczbie użytkowników przed wdrożeniem dla wszystkich
- wspomaga zwinne wdrażanie produktu (Continuous Deployment), który ma niedokończone funkcje (na danym moment nieaktywne)
Wady:
- przechowujemy nieaktywny kod w repozytorium kodu
- tworzymy dług technologiczny dla aplikacji, jeśli nie usuniemy feature toggle po zakończeniu procesu testowania/wdrożenia funkcji na produkcji
- utrudnione testowanie (stosując feature toggles, musimy utrzymywać testy dla aktywnej i nieaktywnej ścieżki)
- narzut na zarządzanie stanem/konfiguracją funkcji
Artykuł Feature Toggle w .NET pochodzi z serwisu DevKR.
]]>Artykuł Uruchomienie polecenia powłoki bash w .NET Core pochodzi z serwisu DevKR.
]]>Process
Do rozpoczęcia procesu (uruchomienia polecania bash) zostanie wykorzystana metoda Start klasy Process z przestrzeni System.Diagnostics. Klasa Process odpowiada za dostęp do procesów lokalnych i zdalnych. W ramach instancji klasy Process mamy możliwość uruchamiania, zatrzymywania, kontrolowania i monitorowania procesu aplikacji.
Bash
Na początek należy sprawdzić ścieżkę do powłoki bash, którą przekażemy do właściwości FileName w ProcessStartInfo. Instancja ProcessStartInfo określa zbiór wartości, które są używane podczas uruchamiania procesu.
which bash
Po wykonaniu polecenia wypisało mi wartość /bin/bash na terminal. W celu prezentacji zaimplementowałem metodę ExecuteCommand w klasie Bash. Możemy także zamiast poniższej metody zaimplementować np. extension method dla stringa.
using System.Diagnostics;
public static class Bash
{
public static (string output, string errorMsg) ExecuteCommand(string command)
{
var startInfo = new ProcessStartInfo
{
FileName = "/bin/bash",
Arguments = $"-c \"{command}\"",
RedirectStandardOutput = true,
RedirectStandardError = true,
UseShellExecute = false,
CreateNoWindow = true
};
string output = null, errorMsg = null;
using (var process = new Process() { StartInfo = startInfo})
{
process.Start();
output = process.StandardOutput.ReadToEnd();
errorMsg = process.StandardError.ReadToEnd();
process.WaitForExit();
}
return (output, errorMsg);
}
}
W bashu zostanie użyta opcja -c, która pozwala przekazać polecenie do wykonania, jako argument. W celu przechwycenie odpowiedzi/błędu i przekierowaniu na wyjście, należy w instancji ProcessStartInfo ustawić parametry RedirectStandardOutput i RedirectStandardError na wartość true. Zobaczmy jak to wygląda w praktyce. Do weryfikacji utworzyłem prostą aplikację konsolową w .NET Core i wywołam dwa polecenia. Pierwsze polecenie ma zwrócić status usługi proftpd (zakończy się sukcesem), a drugie polecenie ma zatrzymać nieistniejącą usługę abc (w tym przypadku otrzymamy błąd na wyjściu).
using System;
using System.Collections.Generic;
class Program
{
static void Main(string[] args)
{
var bashCommands = new List()
{
"service proftpd status",
"service abc stop",
};
foreach (var command in bashCommands)
{
var result = Bash.ExecuteCommand(command);
if(String.IsNullOrEmpty(result.errorMsg) == false)
{
Console.ForegroundColor = ConsoleColor.DarkRed;
Console.WriteLine(result.errorMsg);
};
if(String.IsNullOrEmpty(result.output) == false)
{
Console.ForegroundColor = ConsoleColor.DarkBlue;
Console.WriteLine(result.output);
};
}
Console.ReadKey();
}
}
Czas teraz na sudo dotnet run i otrzymujemy poniższy wynik na terminalu.
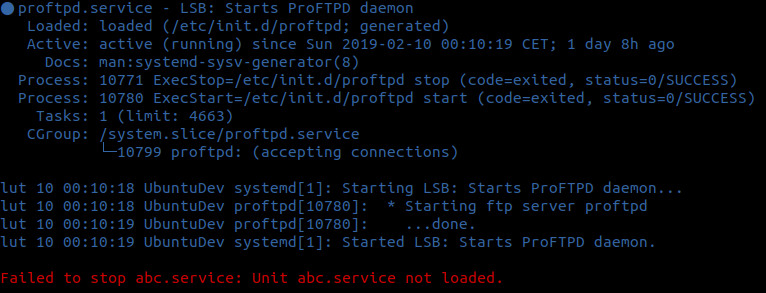
Miało być konkretnie, to czas w tym miejscu zakończyć wpis merytoryczny. Na koniec dodam, że kolejny wpis jeszcze w tym tygodniu. Zapraszam do śledzenia i odwiedzin bloga.
Artykuł Uruchomienie polecenia powłoki bash w .NET Core pochodzi z serwisu DevKR.
]]>Artykuł Snippet w Visual Studio Code pochodzi z serwisu DevKR.
]]>Własny snippet
W celu zdefiniowania własnego snippetu w Visual Studio Code klikamy File -> Preferences -> User Snippets. Następnie wybieramy z listy język programowania. W moim przypadku utworzę snippet w C# reprezentujący szablon metody dla testów jednostkowych w NUnit. Snippet pozwoli mi szybciej zaimplementować metodę testową.
Każdy snippet zdefiniowany jest przez następujące pola:
- name,
- prefix,
- body,
- description.
Celem definiowanego snippetu jest utworzenie szablonu metody testowej w NUnit zgodnego z wzorcem AAA. Nazwa testu będzie odpowiadała konwencji MethodName_StateUnderTest_ExpectedBehavior. Przejście do edycji następnych fragmentów nazwy metody będzie odbywało się poprzez kliknięcie przycisku Tab. Definicja utworzonego snippetu w formacie JSON przechowywana jest w pliku csharp.json (konwencja identyfikator_języka.json).
{
"Create a test method (NUnit)": {
"prefix": "ntm",
"body": [
"[Test]",
"public void ${1:MethodName}_${2:StateUnderTest}_${3:ExpectedBehavior}()",
"{",
"\t//Arrange",
"\tvar sut = GetSUT();",
"\t$0",
"\t//Act",
"\t",
"\t//Assert",
"}"
],
"description": "The template creates a new test method (NUnit)."
}
}
Snippet w VS Code będzie dostępny pod nazwą ntm (NUnit Test Method), każdy może wprowadzić swój prefix. Pole description będzie widoczne z poziomu IntelliSense.

Po wprowadzeniu prefixu ntm klikamy klawisz Tab w celu dodania zdefiniowanego fragmentu kodu z snippetu.
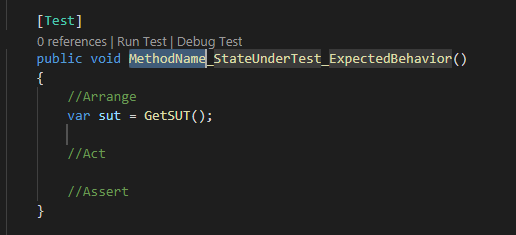
Powyższy fragment kodu zawarty jest w polu body. Jak przyjrzycie się definicji zobaczycie symbole $. Zmienna $0 reprezentuje końcową pozycje kursora w zdefiniowanym fragmencie kodu. Zmienne $1, $2, $3, etc. reprezentują pozycje, na której zatrzyma się kursor po kliknięciu w klawisz tabulacji. W fragmencie powyżej mamy zapis ${1:MethodName} oznacza to, że po przejściu przez kliknięcie klawisza Tab będziemy mogli wprowadzić własny tekst zgodnie z konwencją nazewnictwa testu w miejsce placeholder. W składni snippetów oprócz funkcji tabstops, placeholders istnieje możliwość wykorzystania funkcji choice i variables (Snippet syntax).
Podsumowanie
I to by było na tyle, jeśli chodzi o dodawanie snippetów w VS Code. Na sam koniec zastanówmy się, jakie korzyści daje nam wykorzystanie wstawek kodu:
- poprawa szybkości tworzenia kodu,
- stosowanie/rozpowszechnianie konwencji kodowania poprzez globalny zestaw snippetów w zespole,
- usprawnienie live codingu na prezentacjach. Tworzymy wcześniej snippety o nazwach np. demo1, demo2, demo3, etc. dla bardziej złożonych fragmentów kodu. Tym samym unikamy sytuacji, że nagle coś nie działa i nie tracimy czasu na szukanie błędów.
Artykuł Snippet w Visual Studio Code pochodzi z serwisu DevKR.
]]>Artykuł Jak porównywać obiekty w testach jednostkowych, jeżeli nie przesłonimy metody Equals pochodzi z serwisu DevKR.
]]>System.Object
Typ danych System.Object jest klasą bazową dla wszystkich klas języka C#. Klasa nie wymaga deklarowania dziedziczenia po klasie Object, ponieważ dziedziczenie jest wykonywane niejawnie. Oznacza to, że dowolna instancja klasy zawsze udostępnia metody zdefiniowane w klasie Object: ToString, Equals, GetHashCode i GetType. Zadaniem metody Equals jest porównanie danego obiektu z dowolnym innym obiektem. Domyślna implementacja metody Equals porównuje referencje. Gdy obiekt zostanie porównany z samym sobą otrzymamy wartość true. Przykładowo typ string przesłania metodę Equals i porównuje obiekty na podstawie wartości. Sprawdźmy to w praktyce, zaimplementujmy klasę Driver.
public class Driver
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public Driver(string firstName, string lastName, int age)
{
FirstName = firstName;
LastName = lastName;
Age = age;
}
}
Na podstawie wcześniejszej omawianej teorii wiemy, że domyślna metoda Equals nie zwróci dla klasy Driver wartości true, mimo że obiekty posiadają pola o tej samej wartości. Do implementacji testów jednostkowych został wykorzystany framework NUnit.
[Test]
public void Equals_NotImplementIEquatable_DriversAreNotEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
Assert.AreNotEqual(expectedDriver, actualDriver);
}
Oczywiście możemy napisać test, w którym zostanie sprawdzona każda wartość pola obiektu poprzez wykonanie asercji dla każdej właściwości. W celu uruchomienia wszystkich asercji w teście, asercje zostały wywołane w Assert.Multiple.
[Test]
public void Equals_NotImplementIEquatable_DriversAreEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
Assert.Multiple(() =>
{
Assert.AreEqual(expectedDriver.FirstName, actualDriver.FirstName);
Assert.AreEqual(expectedDriver.LastName, actualDriver.LastName);
Assert.AreEqual(expectedDriver.Age, actualDriver.Age);
});
}
Im więcej obiekt ma właściwości tym więcej instrukcji Assert musimy zdefiniować w teście, co pogarsza czytelność testu. Powyższy test możemy poprawić wydzielając asercje do niestandardowej metody asercji, którą umieścimy w osobnej klasie. Idealnie było by stworzyć obiekt do porównania z ustawionymi właściwościami, a następnie porównać obiekt wynikowy z obiektem oczekiwanym w jednej asercji. Powyższą sytuacje mielibyśmy w przypadku przesłonięcia domyślnej metody Equals w obiekcie. Metodę Equals nadpisujemy implementując interfejs IEquatable
public class Driver : IEquatable{ public string FirstName { get; set; } public string LastName { get; set; } public int Age { get; set; } public Driver(string firstName, string lastName, int age) { FirstName = firstName; LastName = lastName; Age = age; } public bool Equals(Driver other) { if (ReferenceEquals(null, other)) return false; if (ReferenceEquals(this, other)) return true; return Age == other.Age && string.Equals(FirstName, other.FirstName) && string.Equals(LastName, other.LastName); } public override bool Equals(object obj) { if (ReferenceEquals(null, obj)) return false; if (ReferenceEquals(this, obj)) return true; if (obj.GetType() != this.GetType()) return false; return Equals((Driver) obj); } public override int GetHashCode() { unchecked { var hashCode = Age; hashCode = (hashCode * 397) ^ (FirstName != null ? FirstName.GetHashCode() : 0); hashCode = (hashCode * 397) ^ (LastName != null ? LastName.GetHashCode() : 0); return hashCode; } } }
Powyższa sytuacja rozwiązałaby problem, ale nie taki jest cel powyższego wpisu. Zapominamy o przykładowej implementacji interfejsu IEquatable
Sposób nr. 1 – Implementacja IEqualityComparer
Interfejs IEqualityComparer
public class DriverComparer : IEqualityComparer{ public bool Equals(Driver x, Driver y) { if (ReferenceEquals(x, y)) return true; if (ReferenceEquals(x, null)) return false; if (ReferenceEquals(y, null)) return false; if (x.GetType() != y.GetType()) return false; return x.Age == y.Age && string.Equals(x.FirstName, y.FirstName) && string.Equals(x.LastName, y.LastName); } public int GetHashCode(Driver obj) { unchecked { var hashCode = obj.Age; hashCode = (hashCode * 397) ^ (obj.FirstName != null ? obj.FirstName.GetHashCode() : 0); hashCode = (hashCode * 397) ^ (obj.LastName != null ? obj.LastName.GetHashCode() : 0); return hashCode; } } }
Wykorzystamy teraz DriverComparer w celu porównania dwóch obiektów o tych samych wartościach.
[Test]
public void Equals_WhenDriverComparer_DriversAreEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
var driverComparer = new DriverComparer();
Assert.IsTrue(driverComparer.Equals(actualDriver, expectedDriver));
}
Powyższej test możemy lekko zmodyfikować, stosując inną metodę asercji.
[Test]
public void Equals_WhenDriverComparer_DriversAreEqual_V2()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
var driverComparer = new DriverComparer();
Assert.That(actualDriver, Is.EqualTo(expectedDriver).Using(driverComparer));
}
Nic nie stoi nam na przeszkodzie by przetestować także kolekcje obiektów Driver wykorzystując instancje DriverComparer.
[Test]
public void Equals_WhenDriverComparer_DriversCollectionsAreEqual()
{
var actualDrivers = new List
{
new Driver("Adam", "Nowak", 15),
new Driver("Kamil", "Misiek", 16)
};
var expectedDrivers = new List
{
new Driver("Adam", "Nowak", 15),
new Driver("Kamil", "Misiek", 16)
};
var driverComparer = new DriverComparer();
Assert.That(actualDrivers, Is.EqualTo(expectedDrivers).Using(driverComparer));
}
Sposób nr. 2 – BeEquivalentTo z Fluent Assertions
Implementując testy jednostkowe w C# ciągle słyszymy o Xunit, MsTest i NUnit, ale czy istnieją inne alternatywy do pisania asercji. W moim przypadku do implementacji testów wykorzystam bibliotekę Fluent Assertions, która umożliwia pisanie testów w sposób „płynny”. Asercje z Fluent Assertions są zapisane w sposób bardziej naturalny. Sprawia to, że testy jednostkowe mogą być bardziej czytelne dla programisty/testera. Do projektów bibliotekę Fluent Assertions możemy pobrać wykorzystując system dystrybucji bibliotek NuGet. Osoby zainteresowane możliwościami Fluent Assertions zapraszam do lektury dokumentacji. W ramach aktualnych testów interesować będą nas dwie metody Be i BeEquivalentTo. Metoda Be zapewnia, że obiekt jest równy innemu obiektowi przy użyciu implementacji metody System.Object.Equals. W przypadku metody BeEquivalentTo obiekt jest równoważny innemu obiektowi, gdy oba obiekty mają jednakowe właściwości o tych samych wartościach nie zależnie od rodzaju tych obiektów. Załóżmy, że mamy obiekt typu Driver i obiekt typu Client. W przypadku, gdy oba obiekty posiadają właściwości o tych samych nazwach i wartościach, wywołanie metody BeEquivalentTo zakończy się sukcesem. Była teoria teraz czas na testy dla powyższych przypadków.
[Test]
public void Equals_FluentAssertionsUsed_DriversAreNotEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
actualDriver.Should().NotBe(expectedDriver);
}
[Test]
public void Equals_FluentAssertionsUsed_DriversAreEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
actualDriver.Should().BeEquivalentTo(expectedDriver);
}
[Test]
public void Equals_FluentAssertionsUsed_ObjectsAreEqual()
{
var driver = new Driver { FirstName = "Adam", LastName = "Kowalski", Age = 21};
var client = new Client { FirstName = "Adam", LastName = "Kowalski", Age = 21 };
driver.Should().BeEquivalentTo(client);
}
[Test]
public void Equals_FluentAssertionsUsed_DriverAndCustomerAreEqual()
{
var driver = new Driver { FirstName = "Adam", LastName = "Kowalski", Age = 21 };
var customer = new Customer { FirstName = "Adam", Nick = "Kowalski", Age = 21 };
driver.Should().BeEquivalentTo(customer);
}
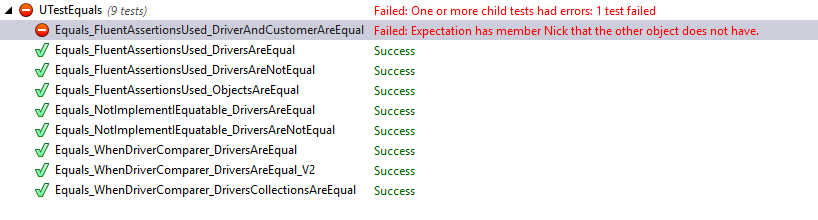
W ramach implementacji testów jednostkowych utworzyłem klasę Client posiadającą takie same właściwości jak Driver, oraz klasę Customer z zmienioną nazwę właściwości z LastName na Nick w porównaniu do klasy Driver. Na potrzeby ostatnich dwóch testów w celu wychwycenia różnic użyłem inicjalizatora obiektu. Ostatni test uzyskał wynik negatywny mimo takich samych wartości ze względu na różnice w nazwie właściwości. Zobaczmy wyniki wszystkich testów w formie graficznej.
Osoby nieczujące potrzeby wykorzystania Fluent Assertions mogą zaimplementować swoją metodę generyczną, która pobierze właściwości z dwóch obiektów o tych samych nazwach i porówna je. Do implementacji będzie wymagane zastosowanie metod z przestrzeni nazw System.Reflection.
Sposób nr. 3 – JSON Serializer
Kolejną alternatywą jest serializacja obiektów do formatu JSON i porównanie ciągów znaków w metodzie Assert.AreEqual.
[Test]
public void Equals_JsonConverterUsed_DriversAreEqual()
{
var actualDriver = new Driver("Adam", "Nowak", 15);
var expectedDriver = new Driver("Adam", "Nowak", 15);
string actualDriverJson = JsonConvert.SerializeObject(actualDriver);
string expectedDriverJson = JsonConvert.SerializeObject(expectedDriver);
Assert.AreEqual(actualDriverJson, expectedDriverJson);
}
Sprawdźmy jak zachowa się test, gdy zmienimy wartość właściwości LastName w jednym obiekcie z Nowak na Kowalski.
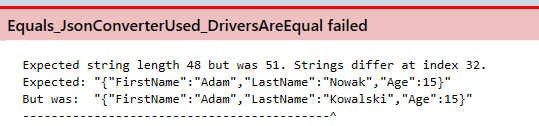
Oczywiście test uzyskał negatywny wynik. W przypadku porównywania JSON-ów szukamy błędu przechodząc pod wskazany indeks w ciągu znaków.
Podsumowanie
W sytuacji, gdy nie chcemy lub nie możemy przesłonić metody Object.Equals w celach testowych, istnieje możliwość zastosowania implementacji IEqualityComparer
Artykuł Jak porównywać obiekty w testach jednostkowych, jeżeli nie przesłonimy metody Equals pochodzi z serwisu DevKR.
]]>